go语言学习笔记 资料 《Go学习路线图》
go语言圣经
Go语言101
https://www.topgoer.com/
位运算符
运算符
描述
实例
&
按位与运算符”&”是双目运算符。 其功能是参与运算的两数各对应的二进位相与。如果对应的位都为1,那么结果就是1, 如果任意一个位是0 则结果就是0
(A & B) 结果为 12, 二进制为 0000 1100
|
按位或运算符”|”是双目运算符。 其功能是参与运算的两数各对应的二进位相或。如果对应的位中任一个操作数为1 那么结果就是1
(A | B) 结果为 61, 二进制为 0011 1101
^
按位异或运算符”^”是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。
(A ^ B) 结果为 49, 二进制为 0011 0001
<<
左移运算符”<<”是双目运算符。左移n位就是乘以2的n次方。 其功能把”<<”左边的运算数的各二进位全部左移若干位,由”<<”右边的数指定移动的位数,高位丢弃,低位补0。
A << 2 结果为 240 ,二进制为 1111 0000
>>
右移运算符”>>”是双目运算符。右移n位就是除以2的n次方。 其功能是把”>>”左边的运算数的各二进位全部右移若干位,”>>”右边的数指定移动的位数。
A >> 2 结果为 15 ,二进制为 0000 1111
匿名结构体 这个例子展示了简单的cache,其使用两个包级别的变量来实现,一个mutex互斥量(§9.2)和它所操作的cache:
1 2 3 4 5 6 7 8 9 10 11 var (make (map [string ]string )func Lookup (key string ) string return v
下面这个版本在功能上是一致的,但将两个包级别的变量放在了cache这个struct一组内:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var cache = struct {map [string ]string make (map [string ]string ),func Lookup (key string ) string return v
我们给新的变量起了一个更具表达性的名字:cache。因为sync.Mutex字段也被嵌入到了这个struct里,其Lock和Unlock方法也就都被引入到了这个匿名结构中了,这让我们能够以一个简单明了的语法来对其进行加锁解锁操作。
一个应用的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 package mainimport ("encoding/json" "fmt" type Screen01 struct {float64 int type Battery struct {string func getJsonData () []byte struct {bool 12 , ResX: 36 , ResY: 36 },"6000毫安" },true ,return jsonDatafunc main () "=========解析(分离)出的数据是===========" )struct {bool "解析(分离)全部结构为:" , allData)struct {"解析(分离)部分结构:" , screenBattery)struct {bool "解析(分离)部分结构:" , batteryTouch)struct {struct {string uint16 "解析(分离)部分不存在的结构" , temp1)struct {string uint16 "解析(分离)完全不存在的结构:" , temp2)
封装 在Go语言中,我们可以对结构体的字段进行封装,并通过结构体中的方法来操作内部的字段。如果结构体中字段名的首字母是小写字母,那么这样的字段是私有的,相当于private字段。外部包裹能直接访问,如果是在名的首字母是大写字母,那么这样的字段对外暴露的,相当于public字段。能够起的方法也是一样的,如果方法名首字母是大写字母,那么这样的方法对外暴露的。
封装的好处:
隐藏实现细节;
可以对数据进行验证,保证数据安全合理。
如何体现封装:
对结构体中的属性进行封装;
通过方法,包,实现封装。
封装的实现步骤:
将结构体、字段的首字母小写;
给结构体所在的包提供一个工厂模式的函数,首字母大写,类似一个构造函数;
提供一个首字母大写的Set方法(类似其它语言的public),用于对属性判断并赋值;
提供一个首字母大写的Get方法(类似其它语言的public),用于获取属性的值。
例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package modelimport "fmt" type person struct {string int float64 func NewPerson (name string ) *person return &person{func (p *person) SetAge (age int ) if age >0 && age <150 {else {"年龄范围不正确.." )func (p *person) GetAge () int return p.agefunc (p *person) SetSal (sal float64 ) if sal >= 3000 && sal <= 30000 {else {"薪水范围不正确.." )func (p *person) GetSal () float64 return p.sal
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport ("fmt" "mytest/encapsulation/model" func main () "smith" )18 )5000 )" age =" , p.GetAge(), " sal = " , p.GetSal())
切片 slice的结构体 1 2 3 4 5 type slice struct {len int cap int
切片和数组的关系
切片的本质是操作数组,只是数组是固定长度的,而切片的长度可变的
切片是引用类型,可以理解为引用数组的一个片段;而数组是值类型,把数组A赋值给数组B,会为数组B开辟新的内存空间,修改数组B的值并不会影响数组A。而切片作为引用类型,指向同一个内存地址,是会互相影响的。
切片的长度:元素的个数
切片的容量:在切片引用的底层数组中从切片的第一个元素到数组最后一个元素的长度(元素数量)
所以判断一个切片是否为空,使用len(s) == 0 判断,不能使用 s==nil 判断
1 2 3 4 5 6 7 8 9 a1 := [...]int {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 }4 ] 2 :] "len(s5):%d cap(s5):%d\\n" , len (s5), cap (s5)) "len(s6):%d cap(s6):%d\\n" , len (s6), cap (s6)) "len(s7):%d cap(s7):%d\\n" , len (s7), cap (s7))
注意:slice是引用类型
当底层数组改变时,不管是切片,还是切片再切片,值都会改变。因为他们使用的是一个内存块,引用的一个内存地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 }2 :] 3 :] 2 ] = 333 "s6:" , s6) "s8:" , s8) 5 ] = 666 "s8:" , s8)
生成切片 初始化一个 slice 有两种方式:
直接声明: 比如 var s []int
使用 make 关键字,比如: s := make([]int, 0)
区别:
直接声明 slice 的方式内部是不申请内存空间的,slice 内部 array 指针指向 null。
使用 make 关键字会申请包含 0 个元素的内存空间 ,底层 array 指针指向申请的内存。
使用json.Marshal序列化的结果是有区别的。
json.Marshal(直接声明): 返回 null
json.Marshal(make关键字初始化): 返回 []
make()函数的第一个参数指定切片的数组类型,第二个参数指定切片的长度,第三个参数指定切片的容量。
1 2 s1 := make ([]int ,5 ,10 )"s1:%v len(s1):%d cap(s1):%d\\n" , s1, len (s1), cap (s1))
扩容机制 只有 append 操作可以触发 slice 的扩容
slice 在初始化时只会申请有限的内存空间,而随着 append 元素的增多,当元素超过当前 slice 的 cap ,就会重新申请一段新内存,把原数据 copy 到这个新内存上,然后 slice 把内部的指针指向这段新内存。
如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)
如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap)
如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)
源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 newcap := old.cap if cap > doublecap { cap else {if old.len < 1024 { else { for 0 < newcap && newcap < cap {4 if newcap <= 0 {cap
demo
如果在函数内部发生了扩容,这时再修改 slice 中的值是不起作用的,因为修改发生在新的 array 内存中,对老的 array 内存不起作用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport "fmt" func main () make ([]int , 3 ,8 )0 ] = 0 1 ] = 1 2 ] = 2 "s =" ,s, cap (s)) append (s,3 ,4 )1 ] = 123 "s =" ,s, cap (s)) "s1=" ,s1, cap (s1)) append (s1,1 ,2 ,3 ,4 ,5 )"s2=" ,s2, cap (s2)) 2 ] = 123 "s =" ,s, cap (s)) "s2=" ,s2, cap (s2))
复制 copy方法是复制了一份,开辟了新的内存空间,不再引用s1的内存地址
1 2 3 4 5 6 7 8 9 10 11 12 13 int {1 , 2 , 3 }var s2 = s1var s3 = make ([]int , 3 )copy (s3, s1) 0 ] = 11 "s1:%v s2:%v s3:%v" ,s1, s2, s3)
删除 删除切片中的元素 不能直接删除 可以组合使用分割+append的方式删除切片中的元素
1 2 3 s3 := []int {1 , 2 , 3 }append (s3[:1 ], s3[2 :]...)
rune rune它是int32的别名(-2147483648~2147483647),相比于byte(-128~127),可表示的字符更多。由于rune可表示的范围更大,所以能处理一切字符,当然也包括中文字符。在平时计算中文字符,可用rune。
字符串修改是不能直接修改的,需要转成rune切片后再修改
1 2 3 4 s2 := "小白兔" rune (s2) 0 ] = '大' string (s3))
只要是双引号包裹的类型就是string,只要是单引号包裹的类型就是int32,也就是rune。和中英文无关。
1 2 3 4 5 6 c1 := "红" '红' "c1的类型:%T c2的类型:%T \\n" , c1, c2) "H" 'H' "c3的类型:%T c4的类型:%T \\n" , c3, c4)
interface Interface 是一个定义了方法签名的集合,用来指定对象的行为,如果对象做到了 Interface 中方法集定义的行为,那就可以说实现了 Interface;
这些方法可以在不同的地方被不同的对象实现,这些实现可以具有不同的行为;
interface 的主要工作仅是提供方法名称签名,输入参数,返回类型。最终由具体的对象来实现方法,比如 struct;
interface 初始化值为 nil;
golang接口定义不能包含变量,但是允许不带任何方法,这种类型的接口叫 empty interface。
使用 type 关键字来申明,interface 代表类型,大括号里面定义接口的方法签名集合。
1 2 3 4 type Animal interface {string string
如下,Dog 实现了 Animal 接口,所以可以用 Animal 的实例去接收 Dog的实例,必须是同时实现 Bark() 和Walk() 方法,否则都不能算实现了Animal接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 type Dog struct {string func (dog Dog) Bark () string ":wan wan wan!" )return "wan wan wan" func (dog Dog) Walk () string ":walk to park!" )return "walk to park" func main () var animal Animal"animal value is:" , animal) "animal type is: %T\\n" , animal) "旺财" }"animal value is:" , animal) "animal type is: %T\\n" , animal)
nil interface
官方定义:Interface values with nil underlying values:
只声明没赋值的interface 是nil interface,value和 type 都是 nil
只要赋值了,即使赋了一个值为nil类型,也不再是nil interface
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 type I interface {type S []int func (i S) Hello () "hello" )func main () var i I"1:i Type:%T\\n" , i)"2:i Value:%v\\n" , i)var s Sif s == nil {"3:s Value%v\\n" , s)"4:s Type is %T\\n" , s)if i == nil {"5:i is nil" )else {"6:i Type:%T\\n" , i)"7:i Value:%v\\n" , i)
output:
其中把值为 nil 的变量 s 赋值i后,i 不再为nil interface
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 1 :i Type:<nil >2 :i Value:<nil >3 :s Value[]4 :s Type is main.S6 :i Type:main.S7 :i Value:[]package mainimport ("fmt" "reflect" type State struct {}func testnil1 (a, b interface {}) bool return a == bfunc testnil2 (a *State, b interface {}) bool return a == bfunc testnil3 (a interface {}) bool return a == nil func testnil4 (a *State) bool return a == nil func testnil5 (a interface {}) bool return !v.IsValid() || v.IsNil()func main () var a *Statenil )) nil ))
反射 反射主要与Golang的interface类型相关(它的type是concrete type),只有interface类型才有反射一说。
在Golang的实现中,每个interface变量都有一个对应pair,pair中记录了实际变量的值和类型:
基本功能 reflect.TypeOf: 直接给到了我们想要的type类型,如float64、int、各种pointer、struct 等等真实的类型
reflect.ValueOf:直接给到了我们想要的具体的值,如1.2345这个具体数值,或者类似&{1 “Allen.Wu” 25} 这样的结构体struct的值
也就是说明反射可以将“接口类型变量”转换为“反射类型对象”,反射类型指的是reflect.Type和reflect.Value这两种
获取接口interface信息 当执行reflect.ValueOf(interface)之后,就得到了一个类型为”relfect.Value”变量,可以通过它本身的Interface()方法获得接口变量的真实内容,然后可以通过类型判断进行转换,转换为原有真实类型。
已知原有类型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package mainimport ("fmt" "reflect" func main () var num float64 = 1.2345 float64 )float64 )
未知原有类型 进行遍历探测其Filed
通过运行结果可以得知获取未知类型的interface的具体变量及其类型的步骤为:
先获取interface的reflect.Type,然后通过NumField进行遍历
再通过reflect.Type的Field获取其Field
最后通过Field的Interface()得到对应的value
通过运行结果可以得知获取未知类型的interface的所属方法(函数)的步骤为:
先获取interface的reflect.Type,然后通过NumMethod进行遍历
再分别通过reflect.Type的Method获取对应的真实的方法(函数)
最后对结果取其Name和Type得知具体的方法名
也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量”
struct 或者 struct 的嵌套都是一样的判断处理方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 package mainimport ("fmt" "reflect" type User struct {int string int func (u User) ReflectCallFunc () "Allen.Wu ReflectCallFunc" )func main () 1 , "Allen.Wu" , 25 }func DoFiledAndMethod (input interface {}) "get Type is :" , getType.Name())"get all Fields is:" , getValue)for i := 0 ; i < getType.NumField(); i++ {"%s: %v = %v\n" , field.Name, field.Type, value)for i := 0 ; i < getType.NumMethod(); i++ {"%s: %v\n" , m.Name, m.Type)
设置变量值 reflect.Value是通过reflect.ValueOf(X)获得的,只有当X是指针的时候,才可以通过reflec.Value修改实际变量X的值,即:要修改反射类型的对象就一定要保证其值是“addressable”的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package mainimport ("fmt" "reflect" func main () var num float64 = 1.2345 "old value of pointer:" , num)"type of pointer:" , newValue.Type())"settability of pointer:" , newValue.CanSet())77 )"new value of pointer:" , num)
调用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package mainimport ("fmt" "reflect" type User struct {int string int func (u User) ReflectCallFuncHasArgs (name string , age int ) "ReflectCallFuncHasArgs name: " , name, ", age:" , age, "and origal User.Name:" , u.Name)func (u User) ReflectCallFuncNoArgs () "ReflectCallFuncNoArgs" )func main () 1 , "Allen.Wu" , 25 }"ReflectCallFuncHasArgs" )"wudebao" ), reflect.ValueOf(30 )}"ReflectCallFuncNoArgs" )make ([]reflect.Value, 0 )
defer 向 defer关键字传入的函数会在函数返回之前运行。
存入的内容以先进后出的方式输出
1 2 3 4 5 6 7 8 9 func main () defer fmt.Println("defer1 runs" )"block ends" )defer fmt.Println("defer2 runs" )"main ends" )
输出:
1 2 3 4 block ends
调用 defer关键字会立刻拷贝函数中引用的外部参数
1 2 3 4 5 6 7 func main () defer fmt.Println(time.Since(startedAt)) defer func ()
Goroutines和Channels 并发和协程 并发协程相关知识
通道 不要让计算通过共享内存来通讯,而应该让它们通过通讯来共享内存。 通道机制就是这种哲学的一个设计结果
我们可以把一个通道看作是在一个程序内部的一个先进先出(FIFO:first in first out)数据队列。 一些协程可以向此通道发送数据,另外一些协程可以从此通道接收数据。
通道可以是双向的,也可以是单向的。
字面形式chan T表示一个元素类型为T的双向通道类型。 编译器允许从此类型的值中接收和向此类型的值中发送数据。
字面形式chan<- T表示一个元素类型为T的单向发送通道类型。 编译器不允许从此类型的值中接收数据。
字面形式<-chan T表示一个元素类型为T的单向接收通道类型。 编译器不允许向此类型的值中发送数据。
一个容量为0的通道值称为一个非缓冲通道(unbuffered channel),一个容量不为0的通道值称为一个缓冲通道(buffered channel)。
1 2 3 ch = make (chan int ) make (chan int , 0 ) make (chan int , 3 )
当一个通道值被赋给另一个通道值后,这两个通道值将共享相同的底层部分。 换句话说,这两个通道引用着同一个底层的内部通道对象。 比较这两个通道的结果为true。
通道的操作
调用内置函数close来关闭一个通道:
传给close函数调用的实参必须为一个通道值,并且此通道值不能为单向接收的。
使用下面的语法向通道ch发送一个值v:
v必须能够赋值给通道ch的元素类型。 ch不能为单向接收通道。 <-称为数据发送操作符。
使用下面的语法从通道ch接收一个值:如果一个通道操作不永久阻塞,它总会返回至少一个值,此值的类型为通道ch的元素类型。 ch不能为单向发送通道。 <-称为数据接收操作符,是的它和数据发送操作符的表示形式是一样的。在大多数场合下,一个数据接收操作可以被认为是一个单值表达式。 但是,当一个数据接收操作被用做一个赋值语句中的唯一的源值的时候,它可以返回第二个可选的类型不确定的布尔值返回值从而成为一个多值表达式。 此类型不确定的布尔值表示第一个接收到的值是否是在通道被关闭前发送的。 (从后面的章节,我们将得知我们可以从一个已关闭的通道中接收到无穷个值。)数据接收操作在赋值中被用做源值的例子:
1 2 v = <-ch
查询一个通道的容量:
cap的返回值的类型为内置类型int。
查询一个通道的长度:
len的返回值的类型也为内置类型int。 一个通道的长度是指当前有多少个已被发送到此通道但还未被接收出去的元素值。
如果一个通道已经关闭了,则它的发送数据协程队列和接收数据协程队列肯定都为空,但是它的缓冲队列可能不为空。
在任何时刻,如果缓冲队列不为空,则接收数据协程队列必为空。
在任何时刻,如果缓冲队列未满,则发送数据协程队列必为空。
如果一个通道是缓冲的,则在任何时刻,它的发送数据协程队列和接收数据协程队列之一必为空。
如果一个通道是非缓冲的,则在任何时刻,一般说来,它的发送数据协程队列和接收数据协程队列之一必为空, 但是有一个例外:一个协程可能在一个select流程控制中同时被推入到此通道的发送数据协程队列和接收数据协程队列中。
一个简单的通过一个非缓冲通道实现的请求/响应的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package mainimport ("fmt" "time" func main () make (chan int ) go func (ch chan <- int , x int ) 3 )make (chan struct {})go func (ch <-chan int ) struct {}{}"bye" )
缓冲通道的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport "fmt" func main () make (chan int , 2 ) 3 5 close (c)len (c), cap (c)) len (c), cap (c)) len (c), cap (c)) len (c), cap (c)) close (c) 7
select流程控制 多路复用可以简单地理解为,N 个 channel 中,任意一个 channel 有数据产生,select 都可以监听到,然后执行相应的分支,接收数据并处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 func main () make (chan string )make (chan string )make (chan string )go func () "firstCh" )go func () "secondCh" )go func () "threeCh" )select {case filePath := <-firstCh:case filePath := <-secondCh:case filePath := <-threeCh:func downloadFile (chanName string ) string return chanName+":filePath"
共享变量的并发 深入源码
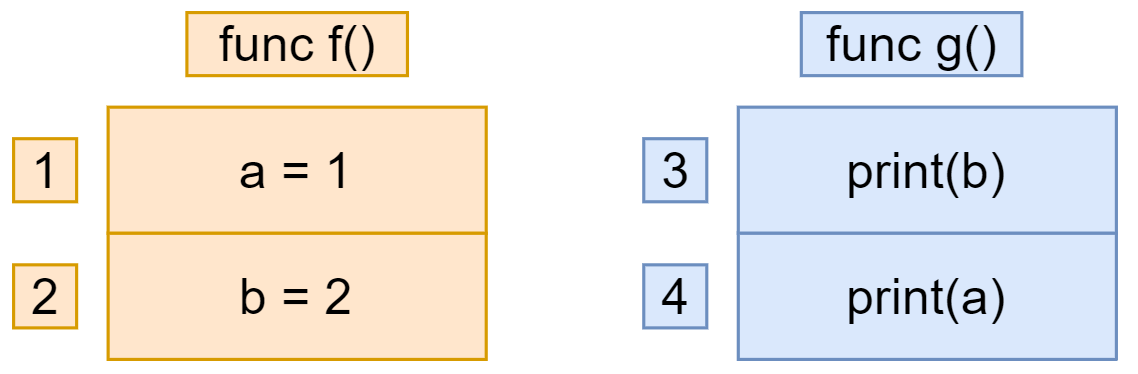
出现的问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport "fmt" var a, b int func f () 1 2 func g () "b=" ,b)"a=" ,a)func main () go f()
以上代码有四种可能的输出
1 2 3 4 b=2 ,a=1 0 ,a=0 0 ,a=1 2 ,a=0
无论任何时候,只要有两个goroutine并发访问同一变量,且至少其中的一个是写操作的时候就会发生数据竞争。并且,在不影响语言规范对 goroutine 的行为定义的时候,编译器和 CPU 会对读取和写入的顺序进行重新排序。
所有并发的问题都可以用一致的、简单的既定的模式来规避。所以可能的话,将变量限定在goroutine内部;如果是多个goroutine都需要访问的变量,使用互斥条件来访问。
sync.Mutex互斥锁 可以使用一个容量只有1的channel来保证最多只有一个goroutine在同一时刻访问一个共享变量。一个只能为1和0的信号量叫做二元信号量(binary semaphore)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var (make (chan struct {}, 1 ) int func Deposit (amount int ) struct {}{} func Balance () int struct {}{} return b
sync包里的Mutex类型可以直接支持。它的Lock方法能够获取到token(这里叫锁),并且Unlock方法会释放这个token。
如果其它的goroutine已经获得了这个锁的话,这个操作会被阻塞直到其它goroutine调用了Unlock使该锁变回可用状态。mutex会保护共享变量。
尽量使用defer来将临界区扩展到函数的结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import "sync" var (int func Withdraw (amount int ) bool defer mu.Unlock()if balance < 0 {return false return true func Deposit (amount int ) defer mu.Unlock()func Balance () int defer mu.Unlock()return balancefunc deposit (amount int )
没法对一个已经锁上的mutex来再次上锁–这会导致程序死锁,没法继续执行下去,Withdraw会永远阻塞下去。
这样的写法是错误的
1 2 3 4 5 6 7 8 9 10 11 func Withdraw (amount int ) bool defer mu.Unlock()if Balance() < 0 {return false return true
sync.RWMutex读写锁 允许多个只读操作并行执行,但写操作会完全互斥
RWMutex需要更复杂的内部记录,所以会让它比一般的无竞争锁的mutex慢一些。
sync.WaitGroup
一个 WaitGroup 对象可以等待一组协程结束 简单使用就是在创建一个任务的时候wg.Add(1), 任务完成的时候使用wg.Done()来将任务减一。使用wg.Wait()来阻塞等待所有任务完成。
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package mainimport ("sync" type httpPkg struct {}func (httpPkg) Get (url string ) var http httpPkgfunc main () var wg sync.WaitGroupvar urls = []string {"<http://www.golang.org/>" ,"<http://www.google.com/>" ,"<http://www.somestupidname.com/>" ,for _, url := range urls {1 )go func (url string ) defer wg.Done()
注意:golang里如果方法传递的不是地址,那么就会做一个拷贝,这里调用的wg根本就不是一个对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func main () var wg sync.WaitGroupmake (chan int , 1000 )for i := 0 ; i < 1000 ; i++ {1 )go doSomething(i, wg, ch)"all done" )for i := 0 ; i < 1000 ; i++ {"from ch:" +strconv.Itoa(dd))func doSomething (index int , wg sync.WaitGroup, ch chan int ) defer wg.Done()"start done:" + strconv.Itoa(index))
应该改为
1 2 3 4 5 go doSomething(i, &wg, ch)func doSomething (index int , wg *sync.WaitGroup, ch chan int )
sync.Once初始化 sync.Once可以保证go程序在运行期间的某段代码只会执行一次,作用与init类似,但是也有所不同:
init函数是在文件包首次被加载的时候执行,且只执行一次。sync.Once是在代码运行中需要的时候执行,且只执行一次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func main () var (for i := 0 ; i < 10 ; i++ {1 )go func (i int ) defer wg.Done()func () "once" , i)
看看源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 type Once struct {uint32 func (o *Once) Do (f func () )if atomic.LoadUint32(&o.done) == 0 {func (o *Once) doSlow (f func () )defer o.m.Unlock()if o.done == 0 {defer atomic.StoreUint32(&o.done, 1 )
在Do()中首先原子性的读取done字段的值是否改变,没有改变则执行doSlow()方法.
一进入doslow()方法就开始执行加锁操作,这样在并发情况下可以保证只有一个线程会执行,再判断一次当前done字段是否发生改变(为什么这里还要在判断一次flag?这里目的其实就是保证并发的情况下,代码块也只会执行一次,毕竟加锁是在doslow()方法内,不加这个判断的在并发情况下就会出现其他goroutine也能执行f()),如果未发生改变,则开始执行代码块,代码块运行结束后会对done字段做原子操作,标识该代码块已经被执行过了.
竞争条件检测 Go的runtime和工具链为我们装备了一个复杂但好用的动态分析工具,竞争检查器(the race detector)。
只要在go build,go run或者go test命令后面加上-race的flag,就会使编译器创建一个你的应用的“修改”版或者一个附带了能够记录所有运行期对共享变量访问工具的test,并且会记录下每一个读或者写共享变量的goroutine的身份信息。
由于需要额外的记录,因此构建时加了竞争检测的程序跑起来会慢一些,且需要更大的内存
race使用指南